
前回はコンテンツに関して URL を利用した ID を作成するところまで進めました。今回は、ロケールの部分を外して、多言語でのクロールの機能を使っていく部分を紹介していきます。

コンテンツ更新
以下のページで最新の情報を確認してください
ロケールの追加
今回は 5 つの言語を利用していきます。まずドメイン設定のページで言語を増やし(スーパーユーザーの権限が必要です)、対象となる言語を追加します。今回は以下の通りです。
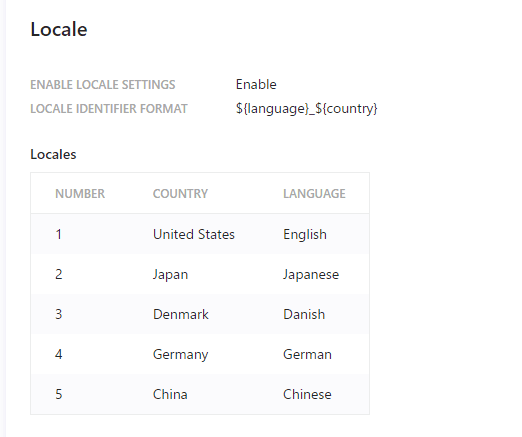
サイトの URL でロケールは以下のような形で今後設定をしていきます。
- ja-jp、de-de、zh-cn の URL を採用している国のサイト
- da (デンマーク語)に関してはロケールではなく言語
- デフォルトの言語は英語
- es-es、fr-fr、it-it に関しては今回は対象外とする
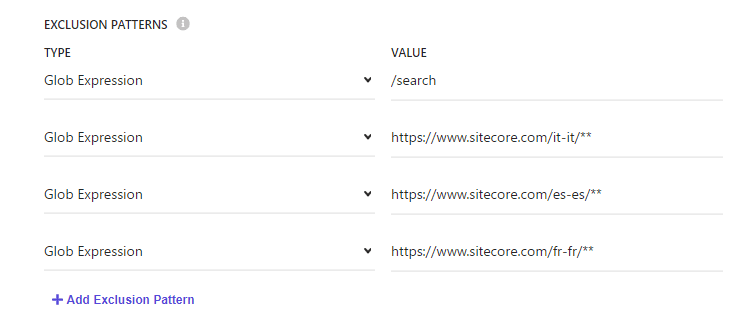
Web Crawler Settings の設定
いくつかの言語に関してはクロール対象外とするために、Exclusion Patters に追加していきます。
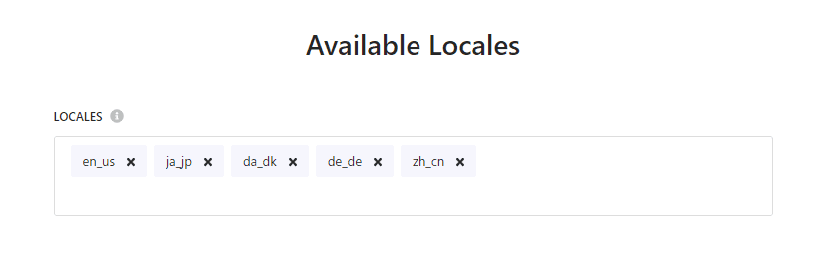
Available Locales の設定
もともと en-us のみを設定していましたが、今回は 5 つの言語を指定します。
Document Extractors の設定
クロールをする設定で、Available Locales の言語が 2 つ以上設定されている場合は、 Document Extractor の個別の Extractor を開くと、以下の画面のように Localized がデフォルトではオフになっています。
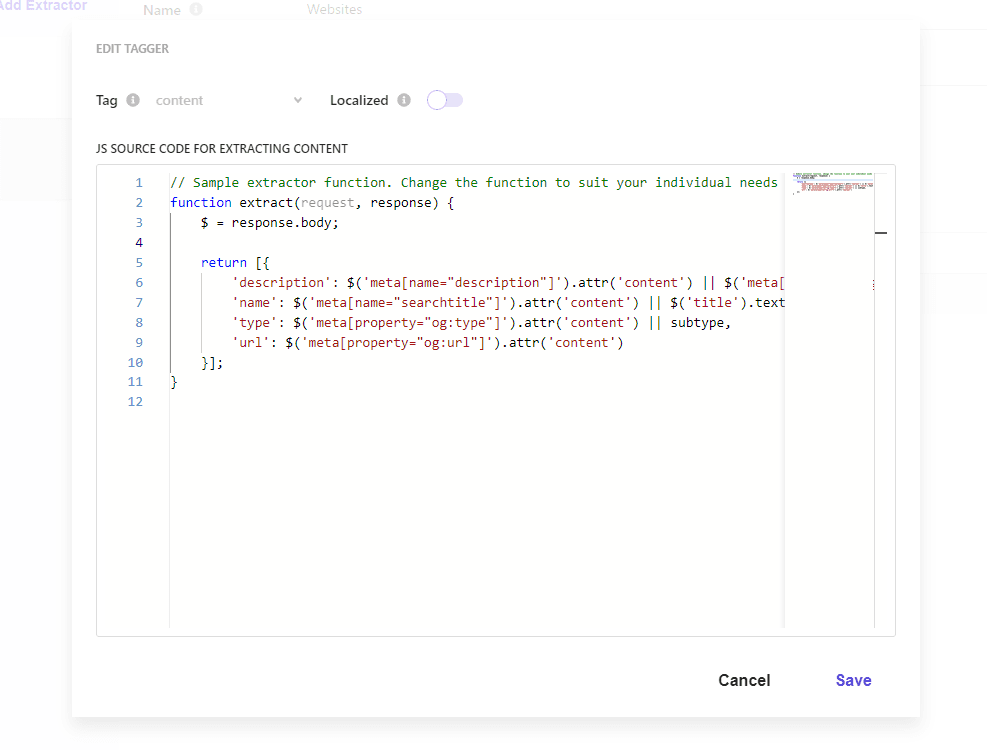
この項目をオンにして、クロールをする際のルールを多言語で利用できるように切り替えます。前回の記事では、URL を利用して ID で判別できるようにしましたが、今回は該当するロケールに関しては削除していきます。このため、以下のようにコードを追加します。
JavaScript
// URL から id を作成する
let url = request.url;
let locales = ['/ja-jp/', '/de-de/', '/zh-cn/', '/da/'];
for (idx in locales) url = url.replace(locales[idx], '/');
let id = url.replaceAll('/', '_').replaceAll(':', '_').replaceAll('.', '_');続いて Locale の取り扱いに関して追加の作業をします。
Locale Extractor の設定
上記の Localized のボタンを有効にした後、ソース設定の項目で Optional となっていた Locale Extractor の設定が To Do となって設定をする必要が出てきます。
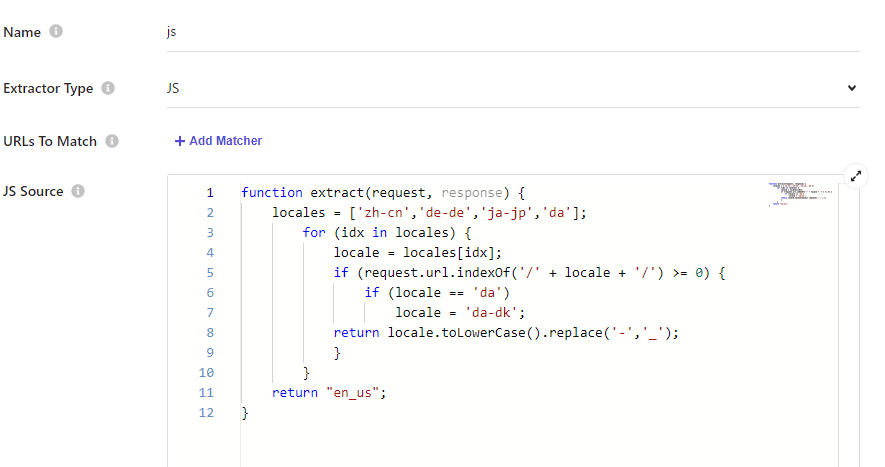
どのロケールとしてコンテンツを認識するかをここで定義をします。以下にサンプルの JavaScript を記載しておきます。
JavaScript
function extract(request, response) {
locales = ['zh-cn','de-de','ja-jp','da'];
for (idx in locales) {
locale = locales[idx];
if (request.url.indexOf('/' + locale + '/') >= 0) {
if (locale == 'da')
locale = 'da-dk';
return locale.toLowerCase().replace('-','_');
}
}
return "en_us";
}コードとしては locales の配列にマッチする場合に、ロケールのデータを指定するようにしています。指定している言語以外は、すべて en-us としています。なお、デンマーク語はロケールではなく言語となっているため、そこだけ if で処理をしてロケールに書き換えています。
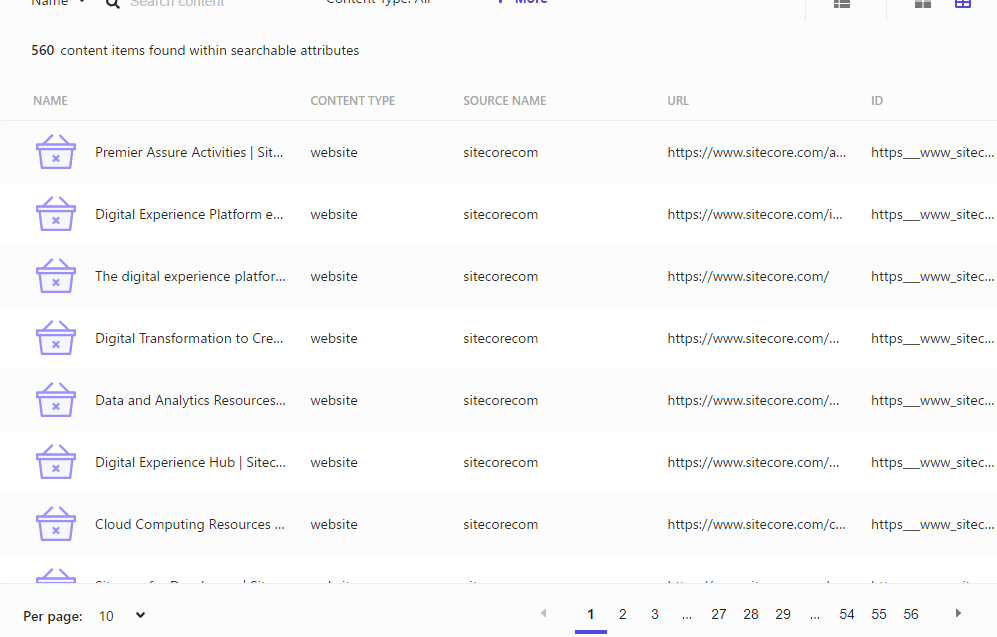
結果は以下のようになります。
クロールに成功した後、コンテンツの一覧を参照すると ID が URL をベースにしているものに代わっているのを確認することができます。
動作確認
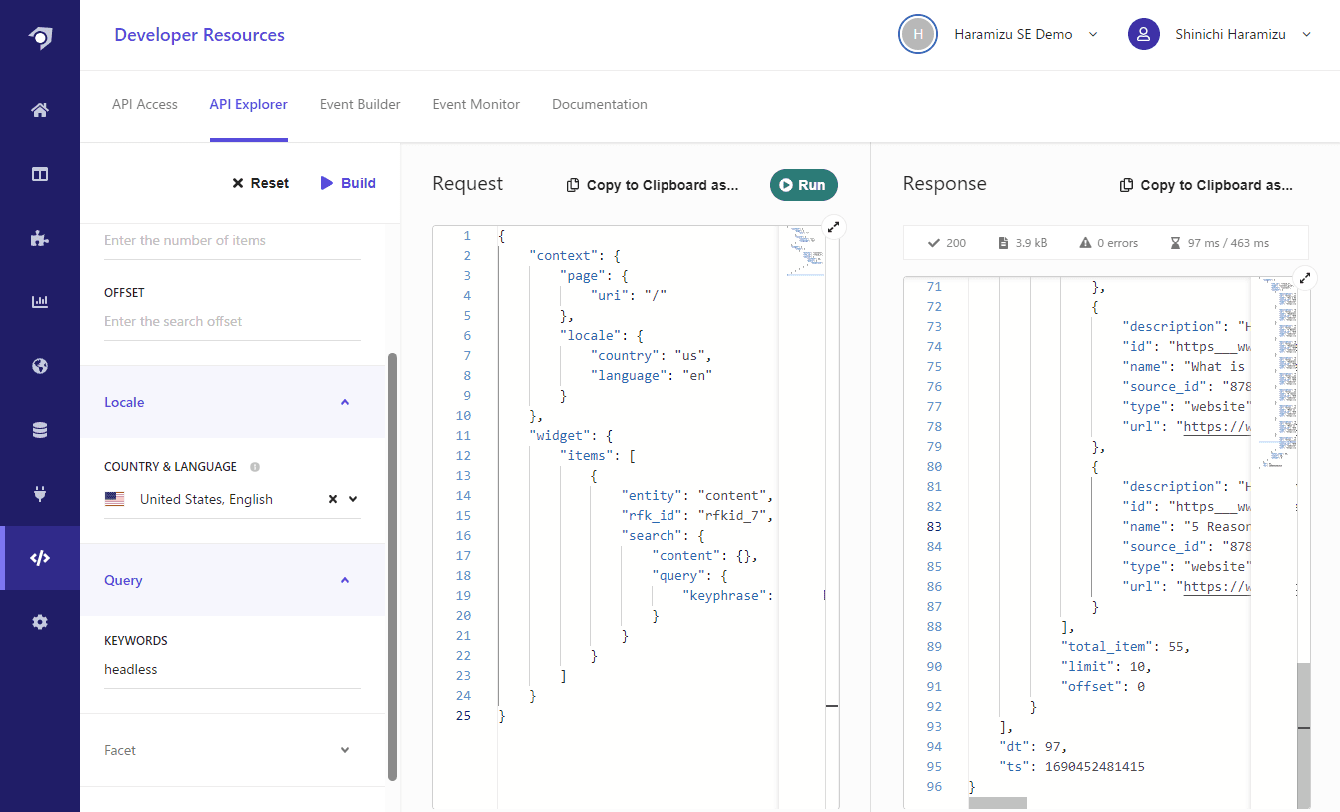
実際に各言語で検索をすることが可能か、Developer Resources の API Explorer を利用して検索して検証をします。
Locale を日本語にして、クエリを生成すると以下のコードが作成されます。
GraphQL
{
"context": {
"page": {
"uri": "/" },
"locale": {
"country": "jp",
"language": "ja"
}
},
"widget": {
"items": [
{
"entity": "content",
"rfk_id": "rfkid_7",
"search": {
"content": {},
"query": {
"keyphrase": "ヘッドレス"
}
}
}
]
}
}実行すると、日本語のページが 10 ページほど結果として表示されます。言語を en-US に切り替えて、キーワードを Headless に変更をして実行すると、55 件の結果のうち 10 件が表示されています。
検索ページでの確認
以前に紹介している Sitecore Search の SDK でサイトを立ち上げている場合、検索ページの言語を切り替えると、同じ検索結果の他の言語のコンテンツを確認することができます。
まとめ
今回は Document Extractor の設定、および Locale Extractor の設定を利用して、言語毎に正しい結果が出るようにソースを作成した形です。より詳しい情報は以下のページで記載されているので、参考にしてください。