
Sitecore Search はクロール型の検索エンジンとなっています。今回は、Search で検索をするためのデータを登録するために、ソースを利用して取得していきます。

コンテンツ更新
以下のページで最新の情報を確認してください
ソースの追加
管理画面の左側、プラグのアイコンがクロールをするための情報を入れる設定画面となります。

クリックをすると最初は何も入っていないソースの画面となります。右上にある Add Source のボタンをクリックしてください。
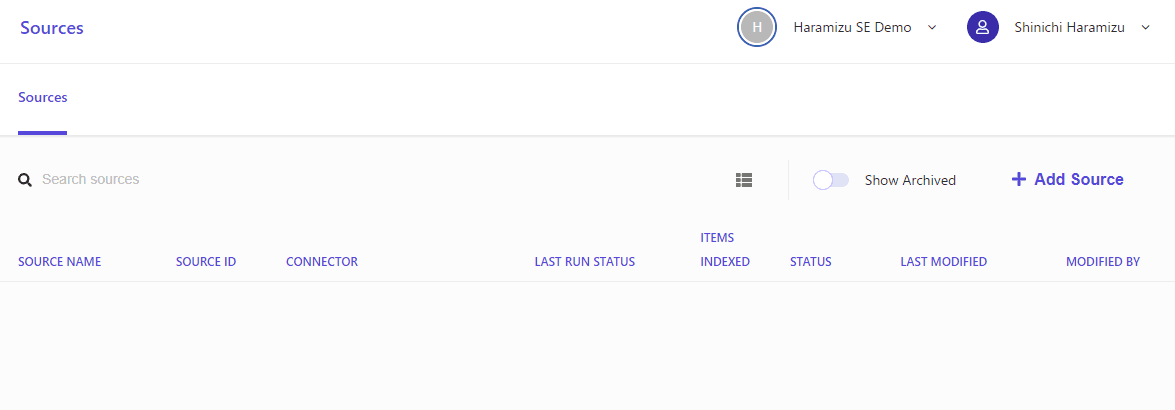
追加するソースに関するリソースを設定していきます。今回は以下のデータを入れていきます。
項目名 | 値 |
|---|---|
Source name | haramizucom |
Description | haramizu.com |
Connector | Web Crawler ( Advanced ) |

Save をクリックして保存をすると新しいソースが追加されます。このソースに関してどういうデータをインポートするのか、というのを設定していきます。

Web Crawler Settings
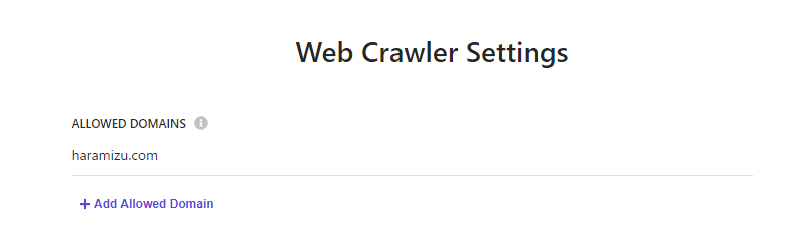
クローラーの動作を設定していきます。まず重要なポイントとして、URL を利用してクロールしていく際には、Allowed Domain の項目があります。この項目が空欄の場合、クロールをしたページに外部向けのリンクがある場合、そのリンクに関してもクロールをする形となります。今回はサイト内だけですので、 haramizu.com を設定します。
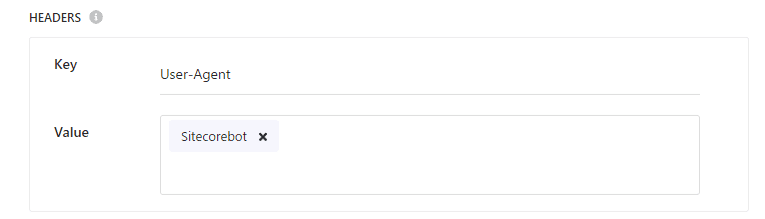
続いてクローラーのエージェントに関する設定をします。これは、Header の項目に設定する形となっており、今回は sitecorebot という名前で設定をします。
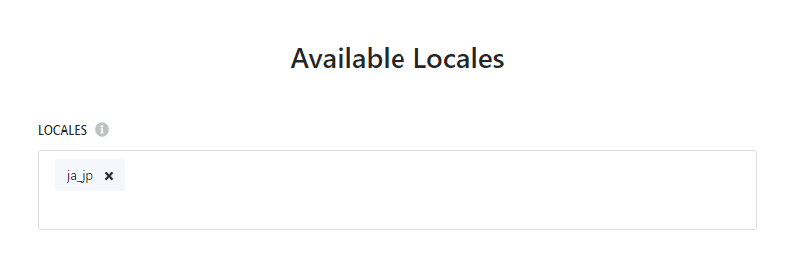
Available Locales
今回のブログは日本語だけなので、クロールをする言語を日本語として設定しておきます。
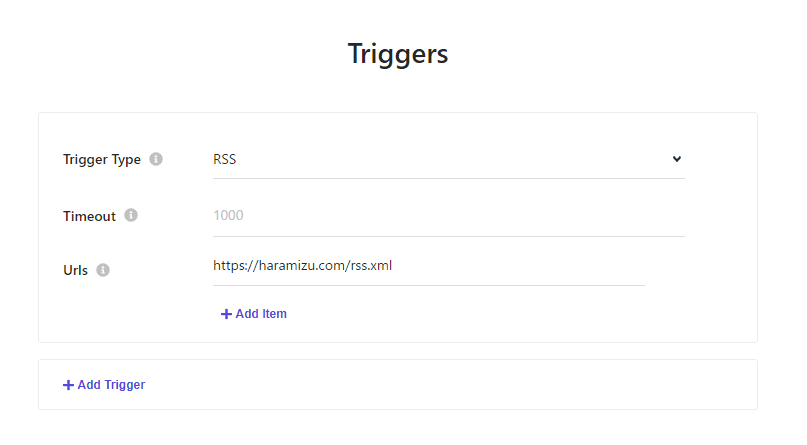
Triggers
トリガーに関しては、今回は RSS フィードを利用します。sitemap.xml なども選択できるため、必要に応じてトリガーを何に設定するのか、という点はサイトのデータを見て選択してください。
Document Extractors
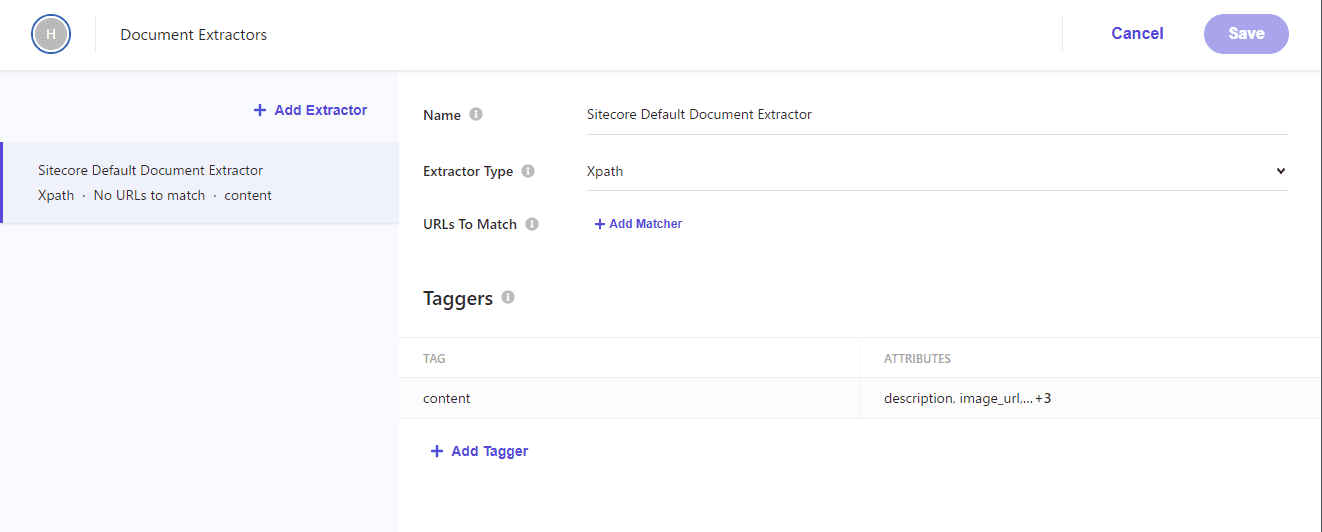
続いての設定は Document Extractors となりますが、翻訳するとドキュメント抽出ツールの設定となります。つまり、クローラーがどの値を取得していくのか、を設定していきます。
今回は初期設定で展開されている Xpath の項目をそのまま利用していきます。
Tagger を見に行くと
Xpath Helper を起動します。Xpath Helper に関しては以前のブログの記事を参照してください。
設定されている Tagger は以下の通りです。
Attribute | Rule type | Rule value |
|---|---|---|
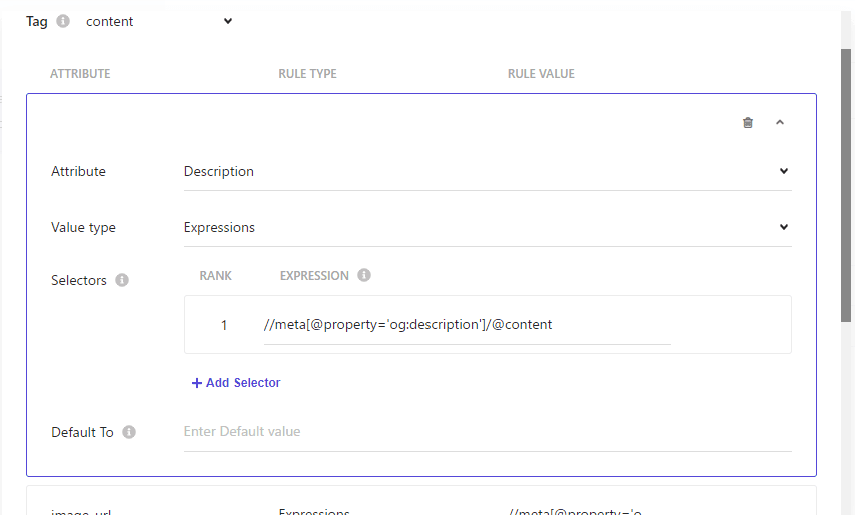
description | Expression | //meta[@property='og:description']/@content |
image_url | Expression | //meta[@property='og:image']/@content |
name | Expression | //meta[@property='og:title']/@content |
type | Expression | //meta[@property='og:type']/@content |
url | Expression | //meta[@property='og:url']/@content |
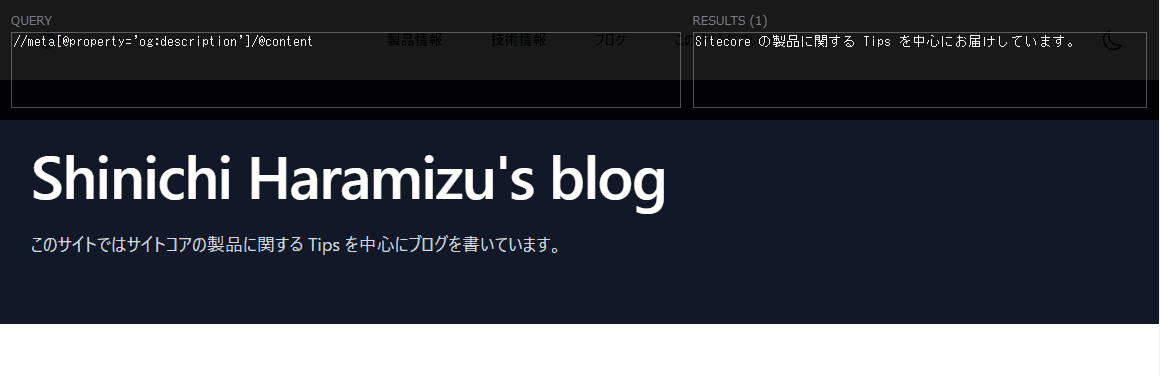
Rule Value を Xpath Finder を利用してページでデータを取得できるか確認をしてください。下の画面は、Description を利用して確認をしている画面です。
クロールの開始
上記の設定が完了したところで、Publish のボタンをクリックしてください。以下のようにダイアログが表示されます。
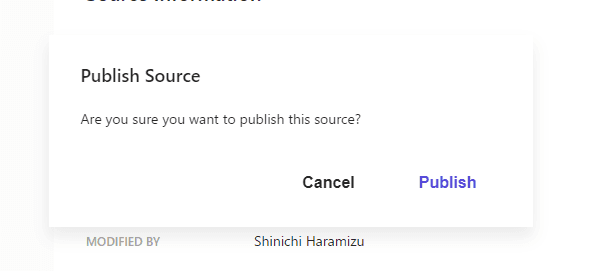
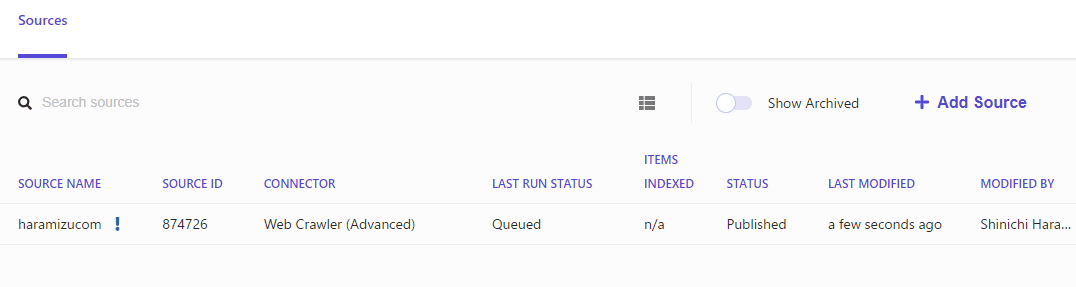
クローラーのキューに追加されて、データが揃うのをしばらく待ちます。
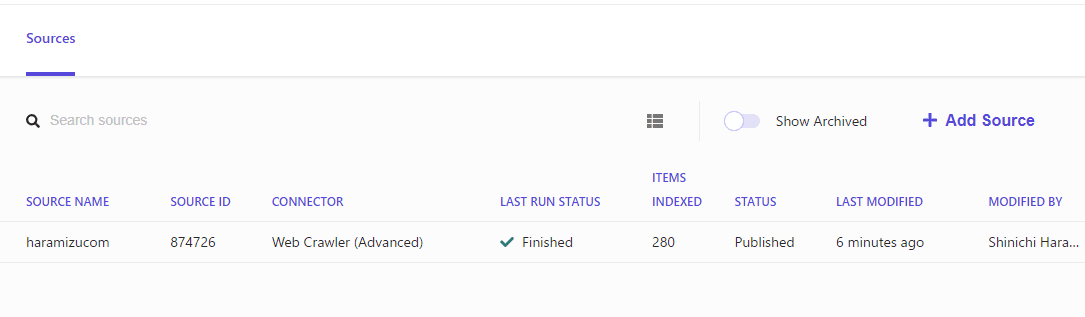
しばらくするとクロールが完了して、データが Search に格納される形となります。
まとめ
今回はクローラーの設定まで進めていきました。次回はインポートされたコンテンツがどういう形で格納されているのかを確認したいと思います。