
In the last issue, we proceeded to create URL-based IDs with respect to content. This time, we will remove the locale part and introduce the part where we will use the multilingual crawling functionality.

Content Update
Please check the latest information on the following page
Add locale
We will use 5 languages in this case. First, go to the Domain Settings page to add more languages (superuser privileges are required) and add the target language. In this case, we will use the following
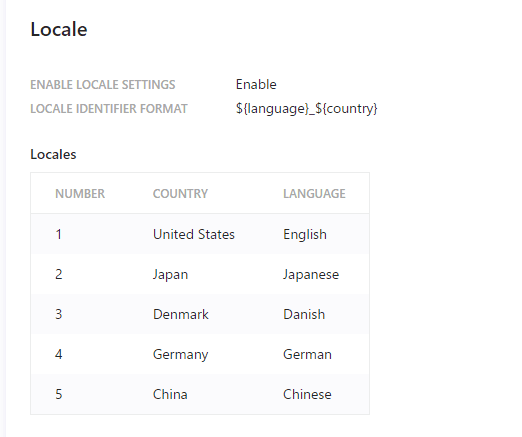
The locale will be set up in the future with the URL of the site as follows
- Sites in countries that have adopted ja-jp, de-de, or zh-cn URLs
- As for da (Danish), it is a language, not a locale.
- Default language is English
- The es-es, fr-fr, and it-it are not included in the scope of this study.
Configure Web Crawler Settings
For some languages, we will add them to the Exclusion Patters to exclude them from crawling.
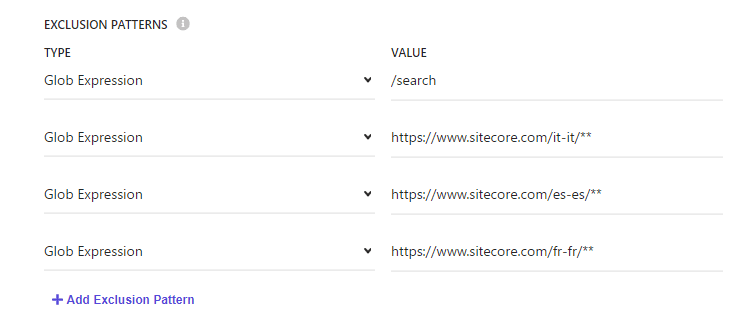
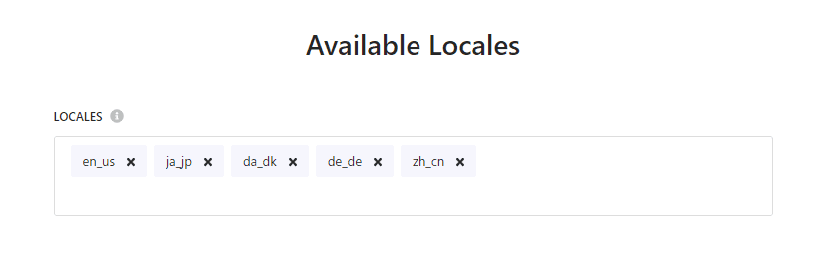
Setting Available Locales
Originally, only en-us was set, but now five languages are specified.
Document Extractors Setting
If two or more languages are set for Available Locales in the crawl settings, Localized is turned off by default when opening individual Extractors in the Document Extractor, as shown in the following screen.
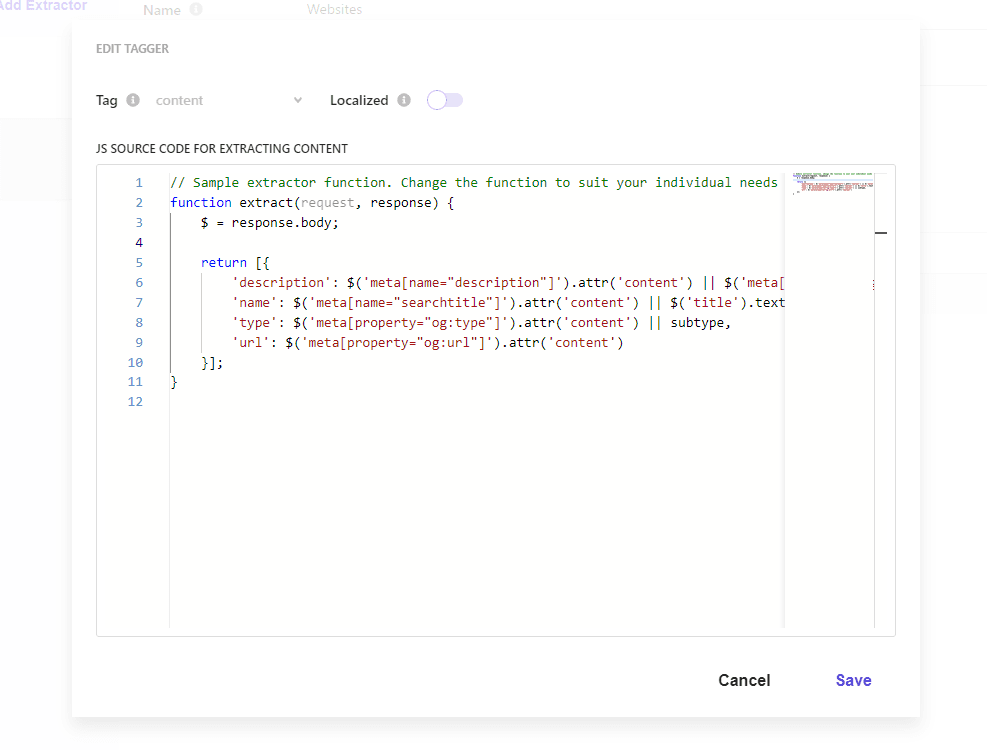
Turn on this item to switch the rules for crawling to be available in multiple languages. In the previous article, we made it possible to identify by ID using URLs, but this time we will remove it with respect to the relevant locale. For this purpose, add the following code
JavaScript
// URL から id を作成する
let url = request.url;
let locales = ['/ja-jp/', '/de-de/', '/zh-cn/', '/da/'];
for (idx in locales) url = url.replace(locales[idx], '/');
let id = url.replaceAll('/', '_').replaceAll(':', '_').replaceAll('.', '_');Additional work is then done on Locale handling.
Locale Extractor Settings
After enabling the Localized button above, the Locale Extractor setting, which had become Optional in the Source Settings item, becomes a To Do and needs to be set.
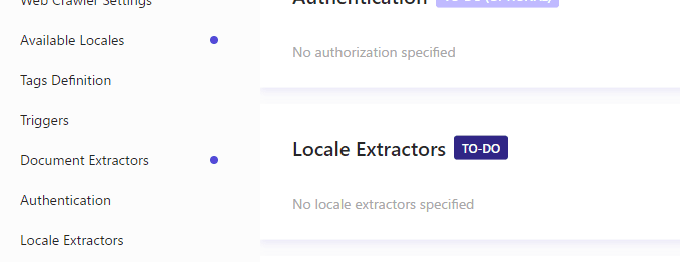
This is where you define the locale in which to recognize the content. A sample JavaScript is provided below.
JavaScript
function extract(request, response) {
locales = ['zh-cn','de-de','ja-jp','da'];
for (idx in locales) {
locale = locales[idx];
if (request.url.indexOf('/' + locale + '/') >= 0) {
if (locale == 'da')
locale = 'da-dk';
return locale.toLowerCase().replace('-','_');
}
}
return "en_us";
}The code is to specify the locale data if it matches the locales array. All other languages are assumed to be en-us, except for the language specified. Note that Danish is not a locale but a language, so only there is an if processed and rewritten to the locale.
The results are as follows
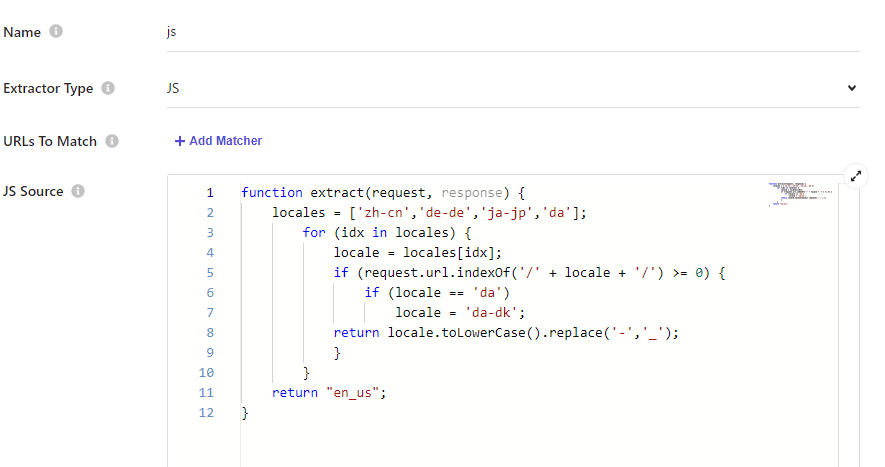
After a successful crawl, you can browse the list of contents to see that the ID has been replaced with one based on the URL.
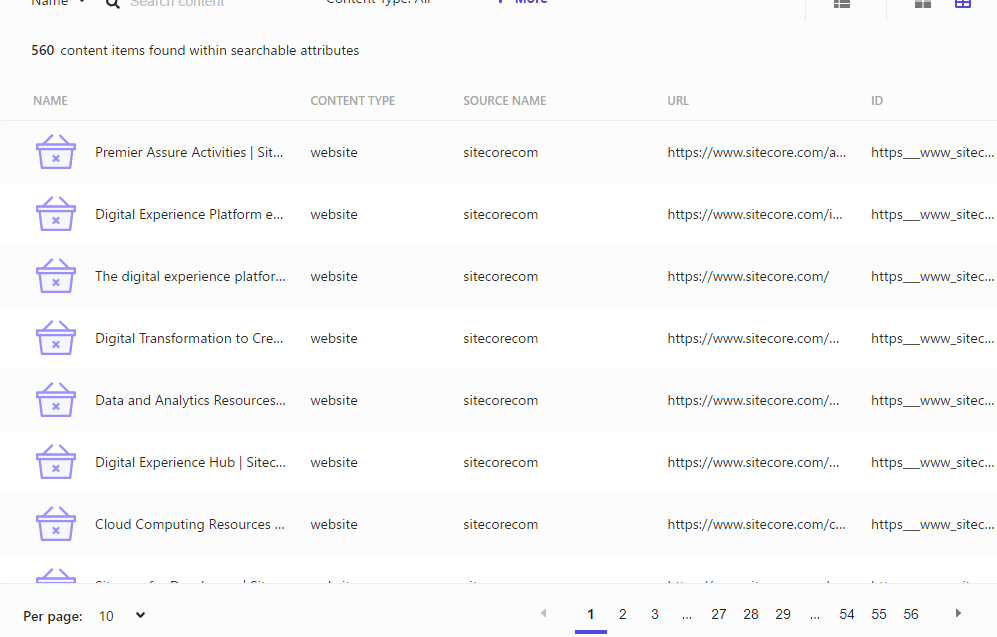
Confirmation of operation
We will verify if it is actually possible to search in each language by using the API Explorer in Developer Resources.
If Locale is set to Japanese and the query is generated, the following code is produced.
GraphQL
{
"context": {
"page": {
"uri": "/" },
"locale": {
"country": "jp",
"language": "ja"
}
},
"widget": {
"items": [
{
"entity": "content",
"rfk_id": "rfkid_7",
"search": {
"content": {},
"query": {
"keyphrase": "ヘッドレス"
}
}
}
]
}
}When executed, about 10 pages in Japanese are displayed as results. Switching the language to en-US and changing the keyword to Headless, 10 out of 55 results are displayed.
Confirmation on the search page
If you have launched your site with the previously mentioned Sitecore Search SDK, you can switch the language of the search page to see content in other languages of the same search results.
Summary
In this case, we have used the Document Extractor settings and Locale Extractor settings to create the source in a way that produces the correct results for each language. For more detailed information, please refer to the following pages.