
Sitecore Search is a crawl-based search engine. In this article, we will use the source to register data to be retrieved for search by Search.

Content Update
Please check the latest information on the following page
Adding Sources
The plug icon on the left side of the administration screen is the settings screen where you can enter information for crawling.

When you click on the button, you will initially see a blank source screen. Click on the Add Source button in the upper right corner.
We will set up resources related to the sources to be added. In this case, we will include the following data
Name | Value |
|---|---|
Source name | haramizucom |
Description | haramizu.com |
Connector | Web Crawler ( Advanced ) |

Click Save to save the new source. You will be asked to set what kind of data you want to import for this source.

Web Crawler Settings
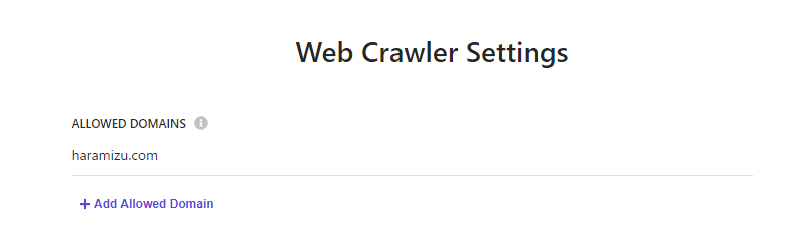
We will configure the crawler behavior. First, it is important to note that when crawling by URL, there is an "Allowed Domain" field. If this field is left blank, the crawler will crawl external links on the crawled page. In this case, we will set "haramizu.com" since it is only within the site.
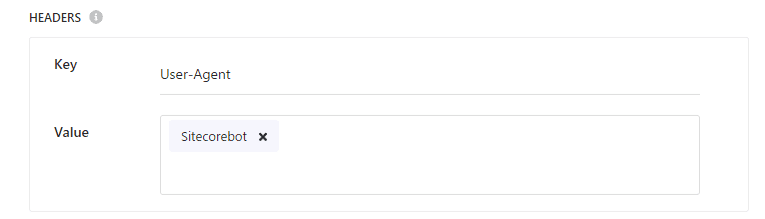
Next, configure the settings for the crawler's agent. This is set in the Header field, this time with the name "sitecorebot".
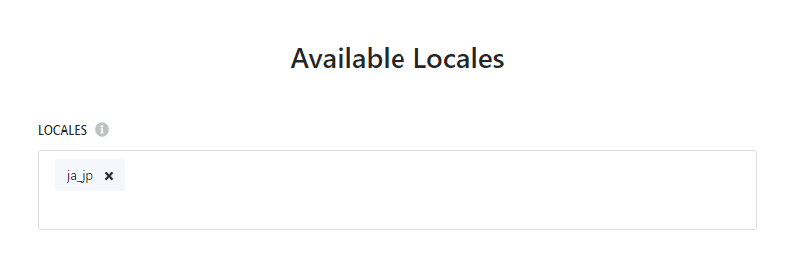
Available Locales
Since this blog is only in Japanese, set the crawl language as Japanese.
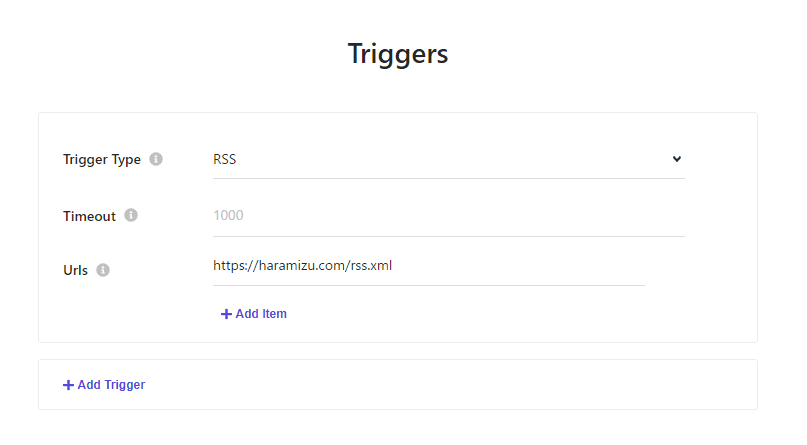
Triggers
For triggers, we will use RSS feeds, but you can also choose to use sitemap.xml, etc. Please look at your site's data to determine what trigger to set if necessary.
Document Extractors
The next setting is Document Extractors, which translates to document extraction tool settings. In other words, we will set which values the crawler will retrieve.
In this case, we will use the Xpath items that are deployed by default.
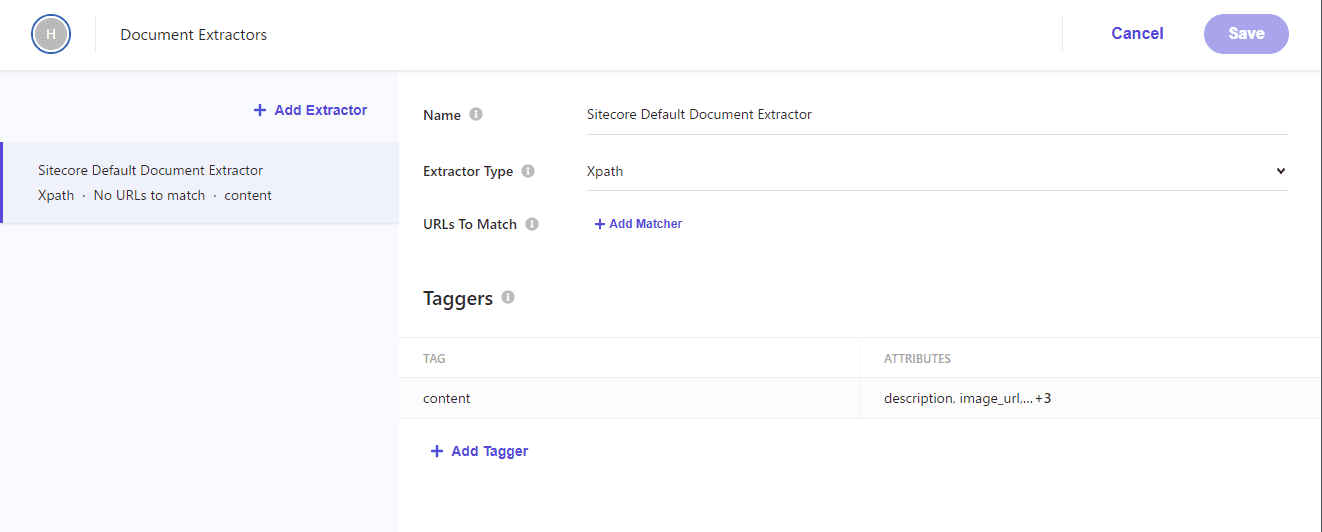
If you go to Tagger.
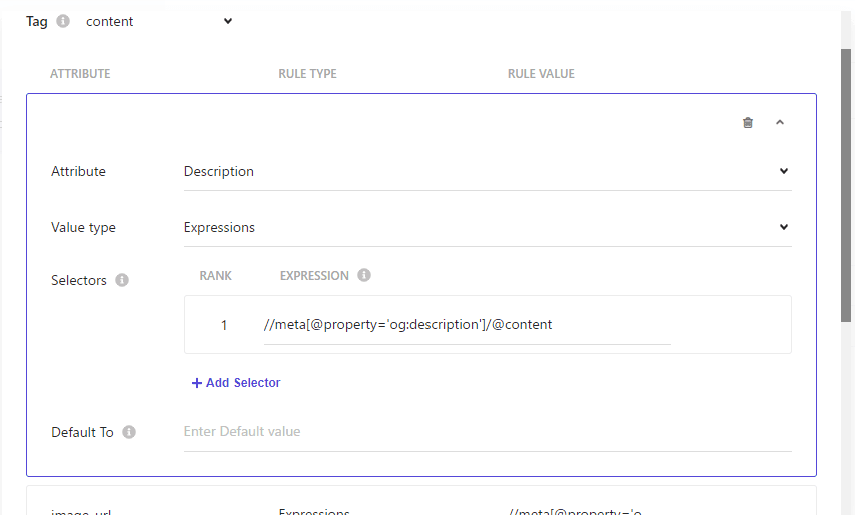
Launch Xpath Helper, see our previous blog post on Xpath Helper.
The Tagger set up is as follows
Attribute | Rule type | Rule value |
|---|---|---|
description | Expression | //meta[@property='og:description']/@content |
image_url | Expression | //meta[@property='og:image']/@content |
name | Expression | //meta[@property='og:title']/@content |
type | Expression | //meta[@property='og:type']/@content |
url | Expression | //meta[@property='og:url']/@content |
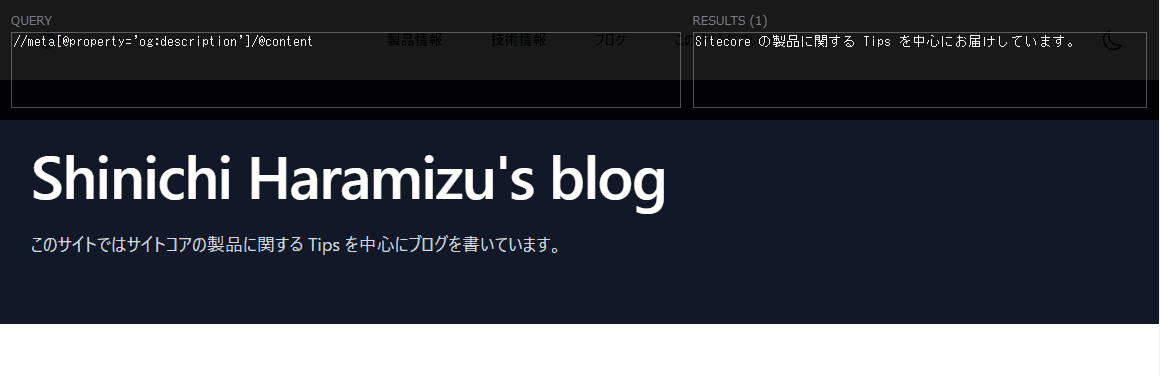
Check if the Rule Value can be retrieved on the page using the Xpath Finder. The screen below shows the screen where the data is checked using the Description.
Start of crawl
After completing the above settings, click the Publish button. A dialog box will appear as shown below.
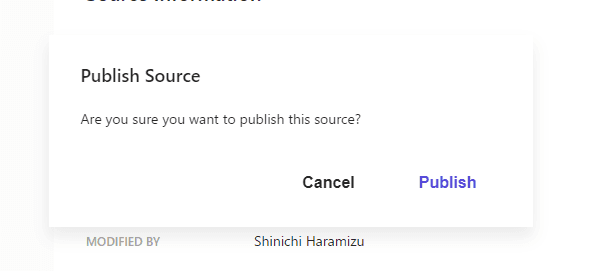
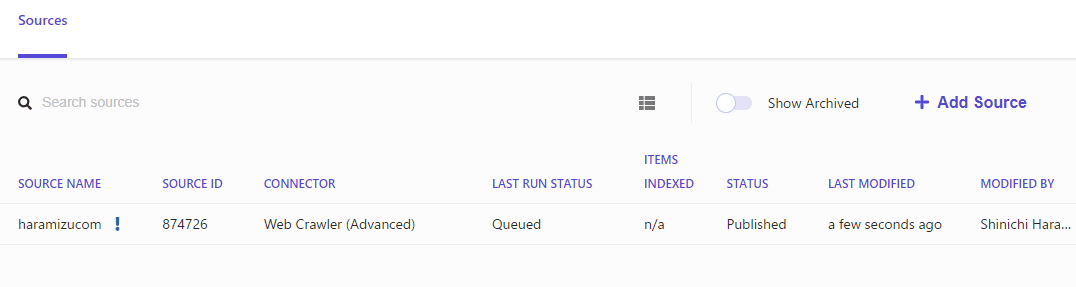
Wait for a while for the data to be added to the crawler's queue.
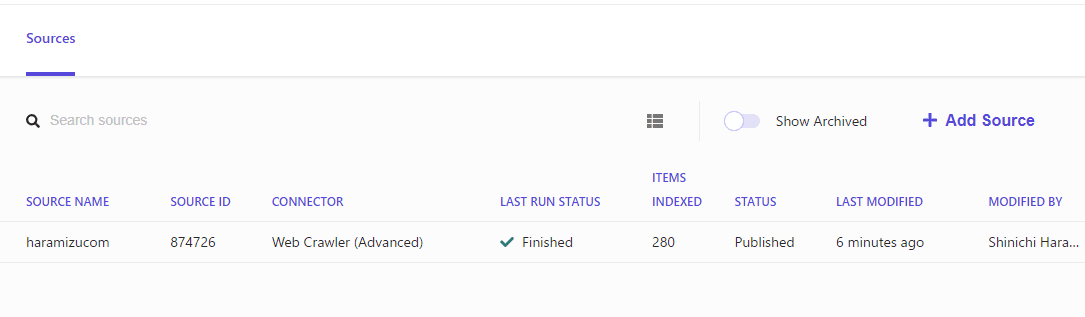
After a short time, the crawl is completed and the data is stored in Search.
Summary
In this issue, we have proceeded to the crawler setup. In the next issue, we would like to check how the imported contents are stored.